In today’s data-driven world, businesses depend on ETL (Extract, Transform, Load) tools to manage and integrate large datasets into data warehouses for analysis and business intelligence. This guide offers a comprehensive overview of ETL processes, tools, benefits, challenges, and best practices.
Understanding ETL: Extract, Transform, Load
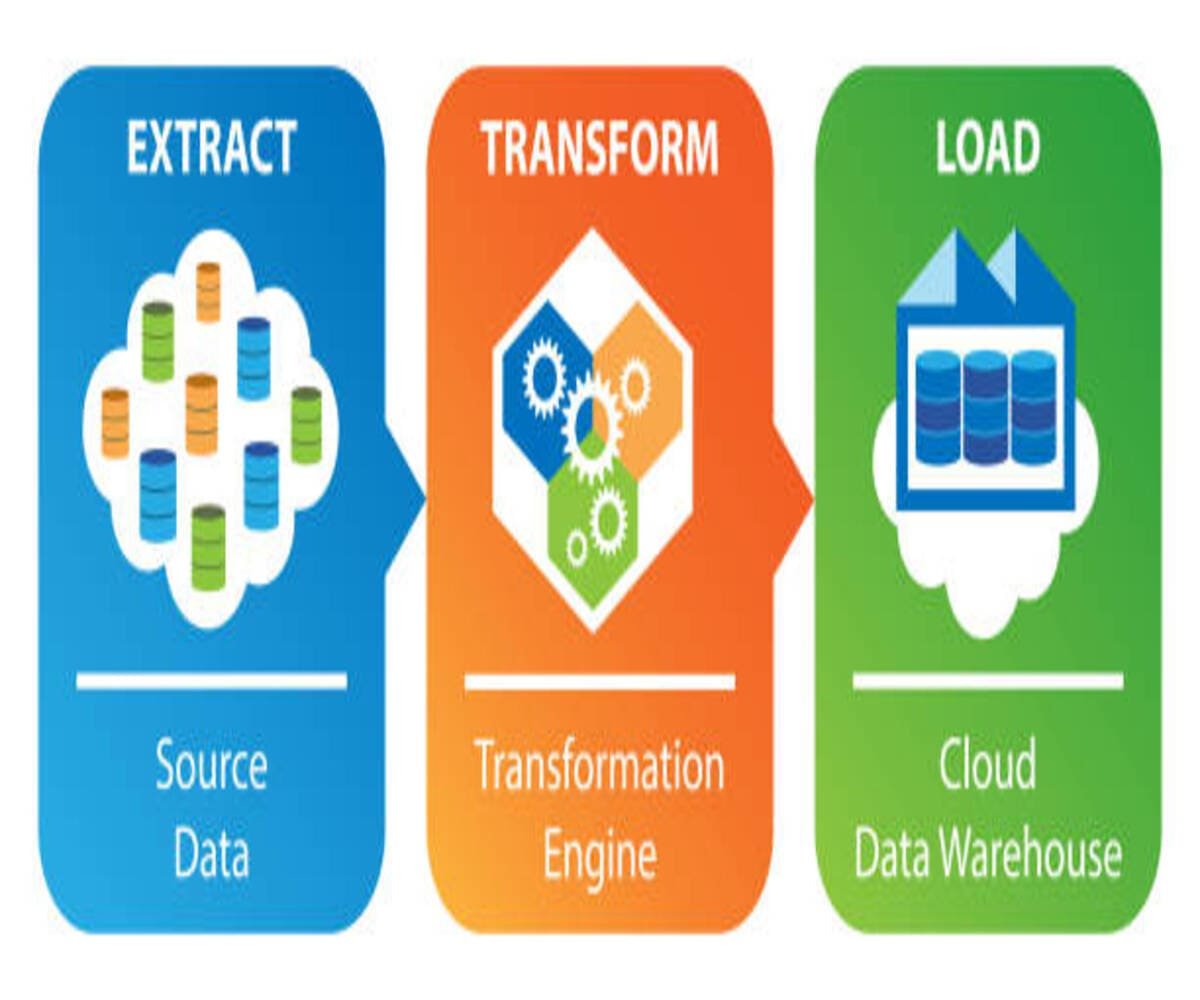
ETL is a fundamental process for integrating data from multiple sources into a centralized repository for analytics and decision-making. The process begins with data extraction from various sources, including databases, APIs, cloud storage, and structured or unstructured files. Once extracted, the data undergoes transformation, which includes cleaning, standardizing, aggregating, and enriching it to ensure consistency. Finally, the processed data is loaded into a data warehouse, where it becomes available for reporting, business intelligence, and advanced analytics.
The Importance of ETL in Data Analytics
The ETL process consolidates data from multiple sources, ensuring improved data quality, accuracy, and consistency. By automating the transformation and integration of data, ETL significantly reduces manual effort and streamlines data management. Businesses rely on ETL tools to scale their data operations, process large datasets efficiently, and generate valuable insights that drive informed decision-making.
The Step-by-Step ETL Process
Extracting data from diverse sources such as relational databases, cloud applications, flat files, and web scraping tools ensures that businesses can compile information from multiple systems. The transformation stage focuses on data cleansing, standardization, deduplication, and aggregation, ensuring that data is structured and ready for analysis. Finally, the load phase moves the processed data into the target data warehouse using full loads, incremental updates, or batch processing, depending on business requirements.
Types of ETL Architectures
Batch processing ETL executes at scheduled intervals, making it ideal for businesses that require periodic updates. Real-time ETL processes data as soon as it is generated, enabling instant analysis and decision-making. Cloud-based ETL solutions provide flexibility and scalability, making them suitable for organizations leveraging cloud technologies. On-premises ETL solutions offer greater security and control, while hybrid ETL models integrate both cloud and on-premises systems to optimize efficiency.
Top ETL Tools and Their Features
Several ETL tools are available, each offering unique capabilities. Apache NiFi is an open-source, scalable ETL tool suitable for real-time data ingestion. Talend provides an intuitive, drag-and-drop interface for creating ETL workflows while ensuring real-time data governance. Microsoft SSIS integrates seamlessly with SQL Server, making it ideal for Microsoft-based environments. Apache Spark specializes in processing large-scale distributed data with batch and real-time capabilities. AWS Glue is a serverless ETL tool that integrates with various AWS services, allowing seamless cloud-based data transformation.
Best Practices for ETL Implementation
Automating ETL workflows minimizes manual intervention, reduces errors, and improves efficiency. Regular data validation and quality checks ensure accuracy and consistency across datasets. Implementing incremental loading optimizes system performance by processing only new or modified records. Monitoring and logging ETL activities help track performance metrics and identify potential issues. Security measures, including compliance with GDPR and HIPAA, protect sensitive business and customer data.
Challenges in ETL Processes
Despite its advantages, ETL presents challenges such as handling inconsistent and unstructured data, managing large datasets efficiently, and optimizing real-time data processing. Organizations may also face integration complexities when connecting various data sources and platforms. Ensuring data security and compliance adds another layer of complexity, requiring robust governance policies. Performance optimization strategies are necessary to reduce latency and ensure smooth execution of data pipelines.
ETL vs. ELT: Key Differences
Traditional ETL transforms data before loading it into a data warehouse, making it ideal for structured environments. ELT (Extract, Load, Transform) reverses this approach by first loading raw data into the data warehouse and performing transformations afterward. ELT is particularly effective for big data and cloud-based architectures, as it leverages the power of modern storage and processing capabilities.
Conclusion
ETL plays a critical role in modern data warehousing and business intelligence, enabling organizations to integrate, clean, and structure data efficiently. Choosing the right ETL tool depends on business needs, data complexity, and scalability requirements. Automating ETL processes improves data accuracy, reduces operational costs, and enhances decision-making. Organizations that implement robust ETL strategies gain a competitive advantage by leveraging high-quality, real-time insights for strategic growth.
By adopting best practices and utilizing advanced ETL tools, businesses can streamline their data integration processes, optimize performance, and drive innovation through data-driven decision-making.








